Graham Mayor
... helping to ease the lives of Microsoft Word users.
 |
 |
 |
Many people access the material from this web site daily. Most just take what they want and run. That's OK, provided they are not selling on the material as their own; however if your productivity gains from the material you have used, a donation from the money you have saved would help to ensure the continued availability of this resource. Click the appropriate button above to access PayPal.
Find and Replace using wildcards
This tutorial pre-supposes that the user will have some basic experience of Word's 'replace' function.
The secret of using wildcard searches is to identify the unique string of text that you wish to find. Wildcards are combined with regular text and formatting options to represent the characters or sequences of characters in that string. Because different combinations of characters can be represented by a variety of wildcard combinations, there is often more than one way of identifying a particular string of text within a document. How you choose to represent that group of characters is therefore a matter of individual preference; and the context of the text within the document will to a great extent dictate the most suitable combination to use on a particular occasion.
Wildcard searches are case sensitive.
Start by identifying the string you wish to replace and then pop up the replace function (CTRL+H) or select Advanced Find from the Editing group on the Home tab of the ribbon (see below); or in earlier Word versions Edit > Replace.
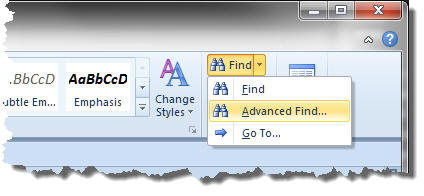
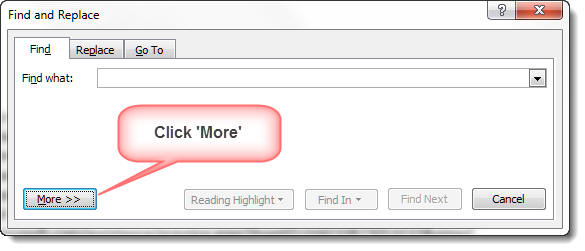
Click the 'More' button to present the additional functions and check the 'Use wildcards' option:
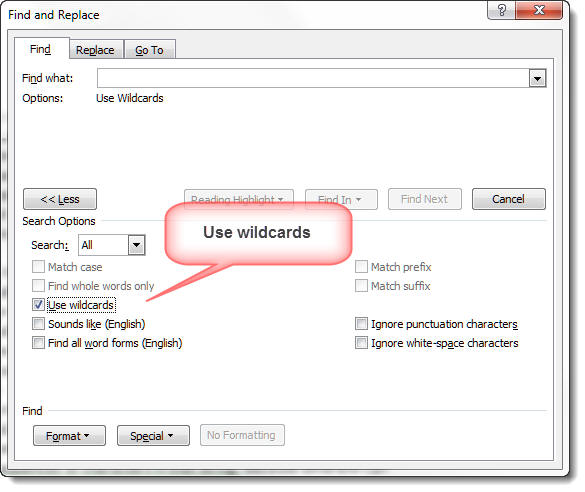
With the cursor in the 'Find what:' or 'Replace with:' boxes you can use keyboard shortcuts to enhance the strings with the principle formatting options e.g CTRL+U - underline, CTRL+I - italics, etc. These operate as toggles to cycle through the various options available.
Insert your find and replace strings using the following guide for inspiration.
| Wildcard | Description | Notes |
| ? and * |
The two most basic wildcards are ? and
*. They are essentially similar in use. ? is used to represent a single character and * represents any number of characters. On their own, these have limited use. s?t will find sat, set,sit ,sot and any other combination of three characters beginning with 's' and ending with 't'. It will also find that combination of letters with a word, thus it would locate the relevant (highlighted) part of inset etc. |
In the quoted example, the asterisk returns st as a
match. Word does not limit the number of characters that the asterisk can match, and it does not require that characters or spaces reside between the literal characters that you use with the asterisk. The asterisk is a rather blunt weapon which must be used with care, as it can return a lot of unwanted results. |
| @ | @ is used to find re-occurrences of the previous character (if any). e.g. lo@t will find lot or loot, ful@ will find ful or full etc. | |
| < > | With any of the above (or any
other combination of wildcards and characters), you can use
the brackets < and
> to mark the start and
end of a word respectively. Thus in the example used above
for '*' <s*t> would find 'secret' and 'serpent', but not 'sailing boats' and 'sign over documents'. Though again, given the use of '*', beware as it will find the block of text from a word starting with 's' to the end of the next word in the document ending with 't', e.g. 'sailing boat' which may not be what you had in mind. The <> brackets can be used in pairs as above or individually as appropriate e.g. ful@> will find 'full' and the appropriate part of 'wilful' but not 'wilfully |
|
| [ ] | Square brackets are always used in pairs and are used to identify
specific characters or ranges of characters. e.g.: [abc] will find any of the letters abc. [F] will find upper case 'F'; [A-Z] will find any upper case letter; [0-9] will find any single number; [13579] will find any odd numbers; [0-9A-Za-z] will find any numbers or letters. The characters can be any character or series of characters, including space. Characters are processed in order - lowest first. If you are uncertain which character is lower than another check with 'Insert > Symbol'. |
|
| [!] |
[!] is very similar to [ ] except in this
case it finds any character not listed in the box
so [!o] would find every character except
“o”.
You can use ranges of characters in exactly the same was as with [ ], thus [!A-Z] will find everything except upper case letters. |
For advanced users only
You can paste any (Unicode) character - unfortunately *not* characters from decorative (Symbol) fonts) - into your search expressions. So copying the first and last characters from the Greek or cyrillic subsets into a search:
[;-ώ] would match any Greek character α β γ δ ε ...
<[Ё-ґ]@> matches any cyrillic word: Вы можете помочь мне? (“Can you help me please?”)
In Word 2000, you can type in Unicode characters with the Alt-key (make sure NumLock is on, then hold down the Alt-key and type the numbers on the numeric keyboard). Since all characters from decorative fonts (Symbol-, Wingdings-fonts ...) are kept in a special code page from &HF000 to &HF0FF, you can search for them with [Alt61472-Alt61695].
| { } | Curly brackets are used for counting occurrences of the
previous character or expression. {n} This finds exactly the number 'n' of occurrences of the previous character {n,} Finds at least the number 'n' occurrences. {n,m} Finds the number of occurrences from 'n' to 'm'. Note: The above examples employ a comma as a list separator {n,m} - for languages that use alternative list separators, substitute the local separator character (often a semi-colon {n;m}) as appropriate. |
Counting can be used with individual characters or more
usefully with sets of characters e.g. [deno]{4} will match done, node, eden) or
bracketed groups: (ts, ){3}
will match ts, ts, ts, . (Unfortunately, there is no wildcard to search for "zero or more occurrences" in Word wildcard searches; [!^13]{0,} does not work). |
| ( ) | Round brackets have no effect on the search pattern, but are
used to divide the pattern into logical sequences,
where you wish to re-assemble those sequences in a different
order during the replace - or to replace only part of that
sequence. They must be used in pairs. The partnering backslash character is used as a replacement string in conjunction with a number to indicate which pair of brackets numbered from the left is required e.g. (John) (Smith) replaced by \2 \1 - note the spaces in the search and replace strings - will produce Smith John or replaced by \2 alone will give Smith. |
The placeholders \1,
\2 etc., can also be
used in the search string to identify recurring text. e.g. Fred Fred could be written (Fred) \1. |
| \ |
If you wish to
search for a character that has a special meaning in
wildcard searches - the obvious example being '?'.
then you can do so by putting a backslash in front of it:
[\?] will find
the question mark character '?' If you wish to find the backslash itself then you need to precede that with a backslash [\\]. The following is a list of the characters that have a special meaning in wildcard searches ( [ ] { } < > ( ) - @ ? ! * \ ) |
See also 'Gremlins to be aware of (for advanced users only)' at the end of this page |
Gotchas
 .
.
You may wish to identify a character string by means of a paragraph mark ¶. The normal search string for this would be ^p.
^p DOES NOT WORK in wildcard search strings! It must however be used in replacement strings, but when searching, you must look for the substitute code ^13.
Wildcard searches will also not find footnote/endnote marks - substitute ^2.
A-z would be expected to reproduce all the letters between A and z i.e. both upper case and lower case letters, which it does, but it reproduces all the characters from ASCII 65 to ASCII 122, and that block also includes the characters [ ] ` ^ _ / Use A-Za-z instead.
The question mark ? is used to find individual characters. If
used with curly brackets to define a range of characters eg
#?{1,3}# it will behave
as an asterisk and find all the characters between the hash
symbols.
Control Codes that may be used with the search/replace tool
| Code | Notes |
| ^1 | In-line picture |
| ^2 | Auto referenced footnotes |
| ^5 | Annotation mark |
| ^9 | Tab |
| ^11 | New line |
| ^12 | Page or Section break |
| ^13 | Paragraph break / 'carriage' return |
| ^14 | Column break |
| ^19 | Opening field brace (when field braces are visible) |
| ^21 | Closing field brace (when field braces are visible) |
| ? | Question mark |
| ^? | Any single character (not valid in the Replace box) |
| ^- | Optional hyphen |
| ^~ | Non-breaking hyphen |
| ^^ | Caret character |
| ^# | Any digit |
| ^$ | Any letter |
| ^& | Contents of 'Find What' box (Replace box only) |
| ^+ | Em dash (not valid in the Replace box) |
| ^= | En dash (not valid in the Replace box) |
| ^u8195 | Em Space Unicode character value search (not valid in the Replace box) |
| ^u8194 | En Space Unicode character value search (not valid in the Replace box) |
| ^a | Comment (not valid in the replace box) (Word 97-2000 only) |
| ^b | Section break (not valid in the replace box) |
| ^c | Replace with Clipboard contents (Replace box only) |
| ^d | Field |
| ^e | Endnote Mark (not valid in the Replace box) |
| ^f | Footnote Mark (not valid in the Replace box) |
| ^g | Graphic (In Line Graphics Only). In Word
2007 a forward slash / also appears to find in-line
graphics. This appears to be an unintentional bug. |
| ^l | New
line -
|
| ^m | Manual Page Break |
| ^n | Column break |
| ^t | Tab
-
|
| ^p | Paragraph Mark -
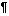 |
| ^s | Non-breaking space |
| ^w | White space (space, non-breaking space, tab); not valid in the Replace box |
| ^nnn | Where "n" is an ASCII character
number Note: ASCII codes below 128 were standardized a long time ago, before the introduction of Windows operating systems. The upper codes were used for OS-specific, localized, or vendor-specific stuff. When DOS code pages were replaced by Windows code pages, a leading zero was used to indicated the difference. Thus ^32 and ^032 will both represent a space character, but ^147 will represent ô and ^0147 will represent “ |
| ^0nnn | See above (Produces ASCII on Macintosh). |
| ^unnnn | Unicode character search where "n" is a decimal number
corresponding to the Unicode character value. Note: Instructions on how to identify the required decimal number are included at the end of this page. |
| Note: | To
search for a specific field, such as an XE (Index Entry)
field, use the following syntax: ^19 field name |
Putting it into practice
Example 1.
There are many occasions when you are presented with blocks of text or numbers etc., where the order of the text is not what you might require in the final document. Swapping the placement of forename and surname as above is one such example - and don't forget you can add to the replacement, even when using bracketed replacements
e.g. you may wish John Smith to appear as Smith, John or, more likely, you may have a column of names in a table, where you wish to exchange all the surnames with all the forenames.

You could do them one at a time, but by replacing the names with wildcards, you can do the lot in one pass.
Let's then break up the names into logical sequences that can only represent the names.
At its simplest, we have here two words - John and Smith. They can be represented by <*>[space]<*> - where [space] is a single press of the spacebar.
Add the round brackets (<*>)[space](<*>) and replace with \2[space]\1
Run the search on the column of names and all are swapped. Run it again and they are swapped back.
If you get it wrong, remember that Word's 'undo' function (CTRL+Z) is very powerful and has a long memory!
Example 2
This could be the changing of UK format dates to US format dates - or vice versa.
7th August 2001 to August 7th, 2001
To give an example of how most of the wildcards could be used in one search sequence to find any UK date formatted above to its equivalent US format date, the following search pattern will do the trick:
[0-9]{1,2}[dhnrst]{2} <[AFJMNSOD]*>[0-9]{4}
Breaking it down [0-9] looks for any single digit number, but dates can have two numbers so to restrict that to two, we use the count function. We want to find dates with 1 or 2 numbers so
[0-9]{1,2}
Next bit is the ordinal 'th'
- Ordinals will be 'st' 'rd' or 'th' so identify those letters specifically:
[dhnrst]
There will always be two letters, so restrict the count to 2
[dhnrst]{2}
Next comes the space. You can insert a space [space]
The month always begins with one of the following capital letters - AFJMNSOD. We don't know how many letters this month has so we can use the blanket '*' to represent the rest. And we are only interested in that word so we will tie it down with <> brackets.
<[AFJMNSOD]*>
there's another space [space] followed by the year. The years here have four numbers so
[0-9]{4}
Finally add the round brackets to provide a logical breakup of the sequence
([0-9]{1,2}[dhnrst]{2})[space](<[AFJMNSOD]*>)[space]([0-9]{4})
and replace with
\2[space]\1,[space]\3
to re-order the sequence.
Example 3
Assume you are parsing addresses and wish to separate the honorific from the name.
American usage puts a full stop (period) at the end ("Mr.", "Mrs.", "Dr.") while British usage often omits the full stop.
([DM][rs]{1,2})( )
will find Mr Mrs Dr
without the stop and
\1.\2
will put one in.
or vice versa
([DM][rs]{1,2}).
will find Mr. Mrs. Dr. with the stop and
\1
will take it out.
Further examples:
(*^13)\1\1 will match any sequence of three identical paragraphs,
(*^13)@ will match any number of replacement paragraphs. Replace with \1 to remove duplicates from a sorted list.
\<([!\<\>]@)\>[!\<\>]@\</\1\> will match any well-formed XML element including start-tag and end-tag
(“<p>some text</p>” or “<customer-name>John Smith</customer-name>”)
By creating logical sequences you can search for almost any combinations of characters.
Gremlins to be aware of (for advanced users only)
Sometimes Word will get confused if it encounters “escaped” brackets \( or \), for example “(\\)” will match *any* character, not only a backslash
Workaround: use "([" instead.
([a-z]\() throws an error - should find an "a(".
Workaround: Use ([a-z][\(]) instead.
Not a bug but still annoying: You have to escape any special character even if you type its code; so ^92 will have the same problems as typing the backslash.
The construction {0,} (find zero or more of the preceding item) is refused as incorrect syntax. This concept is available in Unix regular expression matching, so it's a curious omission.
You don’t always have to “escape” the special characters, if the context makes it clear that the special meaning isn’t wanted. [abc-] matches "-", and [)(] matches ")"
or "(". This may sometimes make your searches behave differently from what you expected.
Establish the unicode decimal number for a character
When searching for a symbol from the extended character set using its unicode decimal number i.e. ^unnnn you first need to identify that number.
First select the first example of the character (e.g. the Cyrillic character ю in the document, then activate the Insert > Symbol dialog.
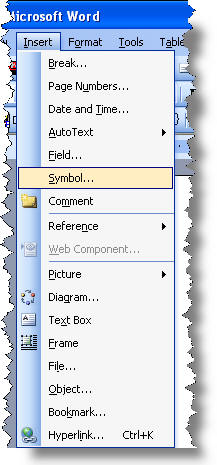
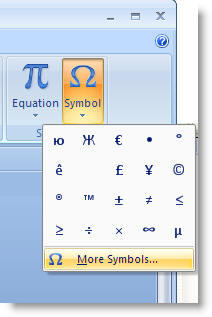
The dialog opens with the character selected:
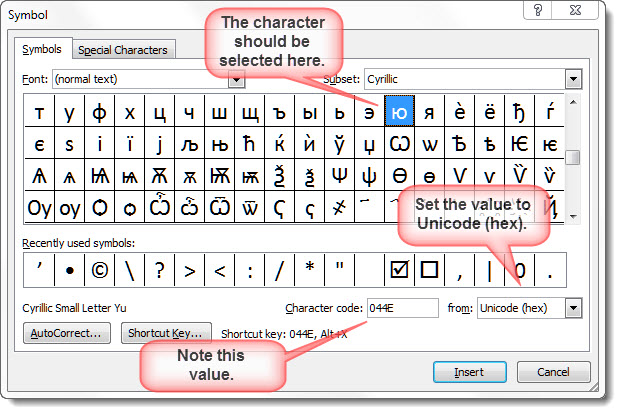
Note the Unicode (hex) character code number - here 044E.
Open the Windows calculator and change its view to the Programmer's calculator, ensure that the Hex radio button is checked and enter the number into the calculator.
In some earlier Windows versions, the calculator has a different layout. The 'hex' and 'dec' conversion buttons are in the Scientific calculator view.
Click the Dec radio button and note the changed number
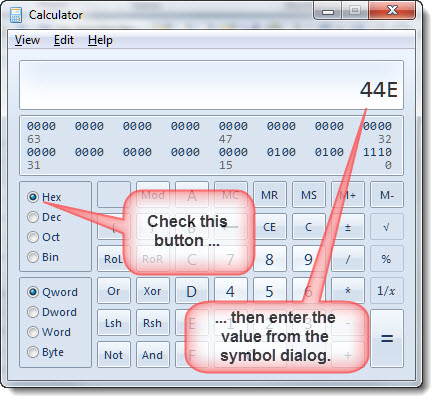
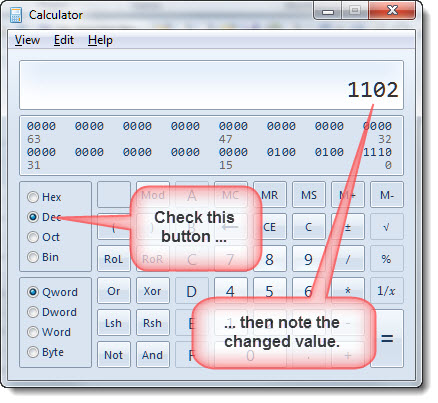
You can then use the four digit number in conjunction with the ^unnn (^u1102) to find the characters in the document.
Macro to identify the four digit number indicated above
The following macro will identify and copy the value of the character at the cursor to the clipboard, for ease of pasting into the find and replace tool's 'Find what' dialog.
If you don't know how to use macro listings, see https://www.gmayor.com/installing_macro.htm.
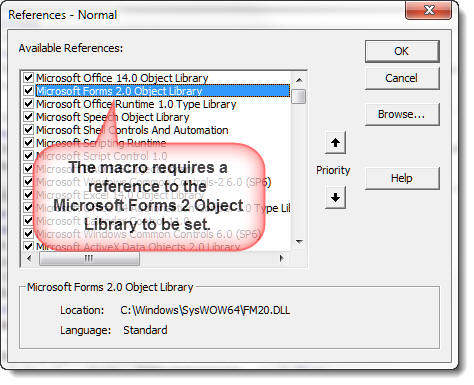
Note that the following macro requires a reference to the Microsoft Forms 2 Object Library to be checked in the vba editor tools > references (see following illustration).
Dim SelFont As Variant
Dim SelCharNum As Long
Dim myData As DataObject
Dim sCode As String
Set myData = New DataObject
Select Case Len(Selection.Range)
Case Is = 0
MsgBox "Nothing selected!"
Exit Sub
Case Is = 1
With Selection
With Dialogs(wdDialogInsertSymbol)
SelFont = .Font
SelCharNum = .CharNum
End With
End With
If SelCharNum < 128 Then
sCode = "^" & SelCharNum
myData.SetText sCode
myData.PutInClipboard
MsgBox "To find this character, use """ & sCode & """ in the 'find what' field." & vbCr & vbCr & _
"This has been copied to the clipboard. Use Ctrl+v to paste into the 'find what' field."
End If
If SelCharNum > 127 Then
sCode = "^u" & SelCharNum
myData.SetText sCode
myData.PutInClipboard
MsgBox "To find this character, use """ & sCode & """ in the 'find what' field." & vbCr & vbCr & _
"This has been copied to the clipboard. Use Ctrl+v to paste into the 'find what' field."
End If
Case Else
MsgBox "Select only the character to evaluate, and run the macro again"
Exit Sub
End Select
End Sub
Introduction
I originally wrote this tutorial, with assistance from fellow Word MVP Klaus Linke for the now defunct Word MVP web site.
However, I felt it desirable to present it here, where I have editorial control, so that I may more easily keep it up to date.